

As a Site Reliability Engineer, my job is to ensure that our website and infrastructure can handle high traffic and unexpected spikes. But today was a particularly big day in my career – the CEO of my company was being interviewed by TF1, the largest TV channel in France, and the interview was going to be broadcast during prime time. With an audience of around 6 million viewers, we knew that there would be a huge influx of traffic to our website, carlili.fr.
We had implemented auto-scaling, but we knew that it wouldn’t be able to react quickly enough to handle such a sudden spike in traffic. The last thing we wanted was for the site to go down during such a high-profile event. So, we had to estimate the number of visitors we were likely to receive and plan an infrastructure that could support that load.
In this article, I’ll be detailing the steps we took to prepare for this event and how we managed to handle the increased traffic without a hitch. From estimating visitor numbers to implementing load testing and scaling strategies, I’ll be sharing our experience and the lessons we learned along the way.

Auto-scaling limitations
Auto-scaling is a process by which a system automatically adjusts the number of resources (such as servers or containers) it is using based on the current demand. This process can take some minutes because it involves several steps:
- Detecting the need for additional resources: The system must first detect that the current resources are not sufficient to handle the demand. This detection can be done using various metrics such as CPU utilization, network traffic, or application-specific metrics.
- Deciding to scale: Once the system detects that additional resources are needed, it must decide whether or not to scale. This decision can be based on various factors such as the current cost of scaling, the expected duration of the increased demand, and the available resources.
- Provisioning new resources: After the decision to scale is made, the system must provision new resources. This can involve allocating new servers, launching new instances in a cloud environment, or increasing the size of existing instances.
- Configuring and deploying new resources: Once new resources are provisioned, they must be configured and deployed. This can include installing software, configuring network settings, and deploying application code.
- Monitoring and testing: Finally, the system must monitor and test the new resources to ensure that they are working correctly and that they can handle the increased demand.
All these steps can take minutes ! At Carlili we absorb the workload by running Docker containers on AWS Fargate and we orchestrate them with AWS ECS. The time required to implement the above steps is as follows :
- Detecting the need for additional resources: our system observes the CPU / RAM consumption of the containers over a period of one minute and triggers an alarm if the maximum consumption over this period exceeds a certain threshold (60%). It can take a second to a minute ⏳
- Deciding to scale: our systems are configured to run the scaling directly
- Provisioning new resources: AWS Fargate guarantees a maximum delay of 30 seconds ⏳
- Configuring and deploying new resources: our containers takes 30 second to a minute to be up ⏳
- Monitoring and testing: 10 seconds to considerate our container healthy and start sending HTTP traffic ⏳
The worst case scenario could therefore take up to 2 minutes. What would happen if thousands of different users came in during this time? The platform would simply go down, an unthinkable solution!
Pre-scaling our platform

I have not yet mentioned the components of our infrastructure that do not have auto-scaling in place : our Databases. Taking into consideration the limit of non-self-scaling components as well as the scaling delay for self-scaling components, it is obvious that it is necessary to pre-scale the platform.
We decided with the management that the platform should be able to absorb 1% of the audience (6 million viewers): 60,000 simultaneous users. But how do you know how many resources are needed to handle such simultaneous traffic? The best solution is to simulate such a traffic via load tests.
Load testing
Load testing is the process of evaluating a system’s performance under a specific expected load. The goal of load testing is to identify any bottlenecks and determine the system’s maximum capacity, so that the system can be optimized and scaled accordingly.
Tools like Apache Bench, JMeter, and Gatling can help with load testing by simulating a large number of users or requests to an application, and measuring its performance and response times under these conditions. Additionally, these tools can be configured to simulate a variety of different use cases and scenarios, allowing us to test for different types of traffic and usage patterns.
Identify bottlenecks
By analyzing the results of load testing, we can identify bottlenecks and potential issues, and make the necessary adjustments to improve the performance and scalability of our applications. Here are the key points to analyze :
On the Backend / Infrastructure side (analyzed with standard monitoring tools) :
- CPU consumption
- RAM consumption
- Internal networking consumption
- maximum simultaneous connexions to databases
On the Frontend side (analyzed with the load testing tools) :
- Response time
- HTTP Response code
After conducting the load testing exercise, we were able to identify the resources required to handle the anticipated traffic. We subsequently established the necessary infrastructure. The final step was to wait and observe the performance of our setup!
What really happened
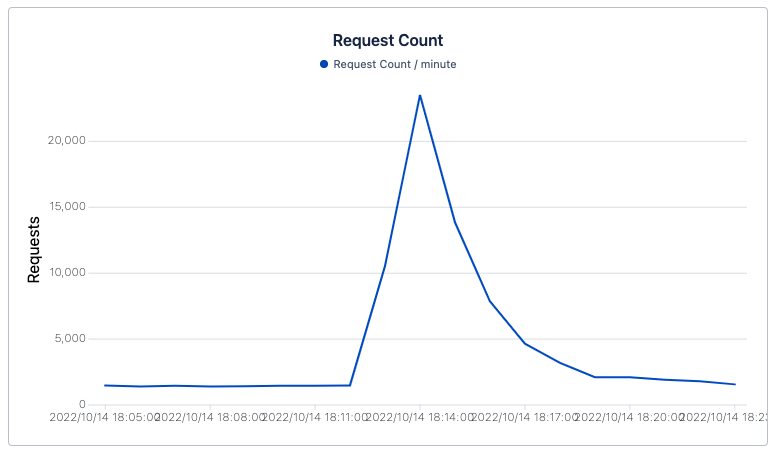
In the end we overestimated the traffic (but it’s better this way). We received about 2000 simultaneous visitors for a 30-second report on our company with the company’s name displayed in small print for about ten seconds on the screen. Scary though, isn’t it?